I guess some request headers are more trustworthy than others.
There's a subset of request headers that can't be modified by a spec-compliant user agent. Let's explore why they're useful for determining how and for what purpose a request was triggered.I got to dabble in some content negotiation recently. I wanted to build an "inspection" page for any image URL served by PicPerf, which would show how effectively the image was optimized. When requested by way of an <img> tag, I'd serve the image, like normal. But when that same URL was directly accessed in the browser's address bar, I’d render some pretty HTML. Here's an example of what I landed on. (I've since changed the URL scheme, but the gist remains).
My first idea to tackle this was to read the request's Accept header, which should only contain the content types a client prefers. For browsers requesting an HTML document, it looks like this:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8But for a request from an <img> tag, the browser instead uses something like this:
Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8It's relatively common for frameworks to leverage this header for negotiating content. Rails has an elegant way of doing it. You might've used it before. The value of the Accept header dictates how the application responds:
class NoodleController < ApplicationController
def show
@noodle = Noodle.find(params[:id])
respond_to do |format|
format.html show.html.erb
format.json { render json: @noodle }
end
end
endThis seemed simple enough for me. If the header included text/html, it was probably from a browser navigation. If not, it's an <img> or CSS requesting the image.
The risk, of course, is that there's always a more-than-zero chance of the Accept header being unexpectedly manipulated (or even wiped) before the server receives it. For example, CDNs have been known to adjust header values, or remove them altogether. And if the request isn't fully owned by the browser itself (such as any fetch() call from your application code), the unpredictability goes up even further. There are no rules preventing me from sending Accept: Jesus, which could cause trouble if the server is expecting a very specific set of values.
I didn't want to deal with any of that. I wanted rock-solid confidence a request was coming straight from the browser's navigation bar.
So, I was pretty happy to find that as long browsers stick to the specification, we can have that confidence. Some header values can be trusted more than others. They're called "forbidden request headers," and can be modified only by the user agent (the browser). Nothing else. I was able to use a very specific set of forbidden headers to accomplish my objective (we'll get to those), but I wanted to dig a little further into them regardless.
Verifying Some Headers Don't Budge
There are actually 20-something different headers that spec-compliant user agents won't allow you to customize. It's unlikely you've had to learn that the hard way – they're not the ones you're typically handling in a request (Content-Type, Access-Control-Allow-Origin, etc.).
To get a feel for this, I set up basic Express server with a couple of routes: one for serving some HTML, and another for receiving a client-side, JavaScript-triggered HTTP request. All that endpoint does is spit out request's headers.
const app = express();
app.get("/page", (req, res) => {
res.sendFile(__dirname + "/index.html");
});
// To be hit by client-side JavaScript:
app.get("/api", (req, res) => {
console.log(req.headers);
res.send("got em");
});Then, it was time to experiment a bit.
via Fetch
The first client-side request I sent came from fetch(). In the request, I tried to set three different request headers. One of them – Host – is forbidden:
<script type="module">
const response = await fetch("http://localhost:3000/api", {
headers: {
"X-Whatever": "lulz",
Accept: "an-invalid-value",
Host: "http://fakehost.com"
},
});
</script>Here's what the server received:
'x-whatever': 'lulz',
accept: 'an-invalid-value'
host: 'localhost:3000'
The first two were were set as expected, but the Host override was completely ignored. I got the same result from Node’s implementation of fetch(), by the way. It also ignored by attempt:
app.get("/", async (req, res) => {
// Server-side `fetch()` request:
await fetch("http://localhost:3000/api", {
headers: {
"X-Whatever": "foolz",
Accept: "an-invalid-value",
Host: "http://fakehost.com",
},
});
return res.send("ok");
});
app.get("/api", (req, res) => {
console.log(req.headers);
// Custom `host` value ignored:
// {
// 'x-whatever': 'foolz',
// accept: 'an-invalid-value',
// host: 'localhost:3000'
// }
});Despite being two very different worlds, the browser-server consistency isn't surprising. Node's fetch API was designed to follow the same specification as the browser implementation. That's made clear in Node's documentation.
via XMLHttpRequest
I gave XMLHttpRequest a shot too:
<script>
const xhr = new XMLHttpRequest();
xhr.open("GET", "http://localhost:3000/api");
xhr.setRequestHeader("X-Whatever", "foolz");
xhr.setRequestHeader("Accept", "an-invalid-value");
xhr.setRequestHeader("Host", "http://fakehost.com");
xhr.send();
</script>Interestingly, it was even more aggressive, spitting out an error and leaving the request stuck in a "pending" status.

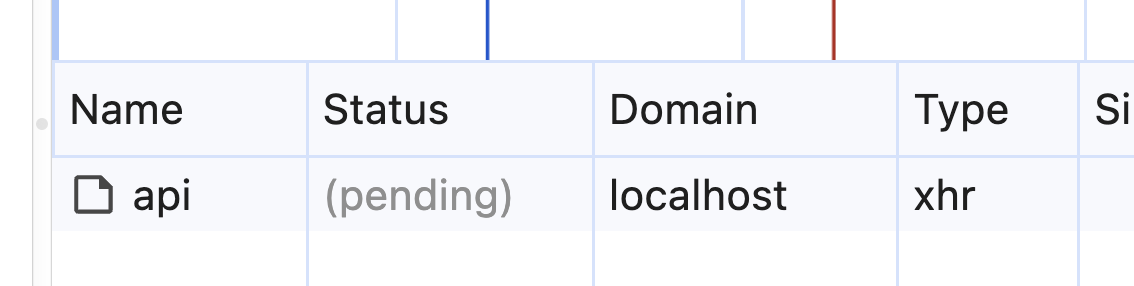
So, if you're looking to override any of those headers in the browser, you're outta luck.
via Cloudflare Worker
Because edge functions, CDNs, and other reverse proxies are so often in the middle of requests, I wanted to verify fetch()'s behavior from within a Cloudflare worker too. I kept it simple. As a request comes in, attempt to override the host:
export default {
fetch(request) {
const newRequest = new Request(
"https://my-temporary-url.ngrok-free.app",
{
...request,
headers: {
...request.headers,
"x-whatever": "foolz",
accept: "an-invalid-value",
host: "fakehost.com",
},
}
);
return fetch(newRequest);
},
};
Same deal. x-whatever and accept were respected, but host was ignored.
Not Everything Respects the Spec
Of course, there are plenty of other tools that weren't built according to these rules. Postman is one of them. This will work just fine:
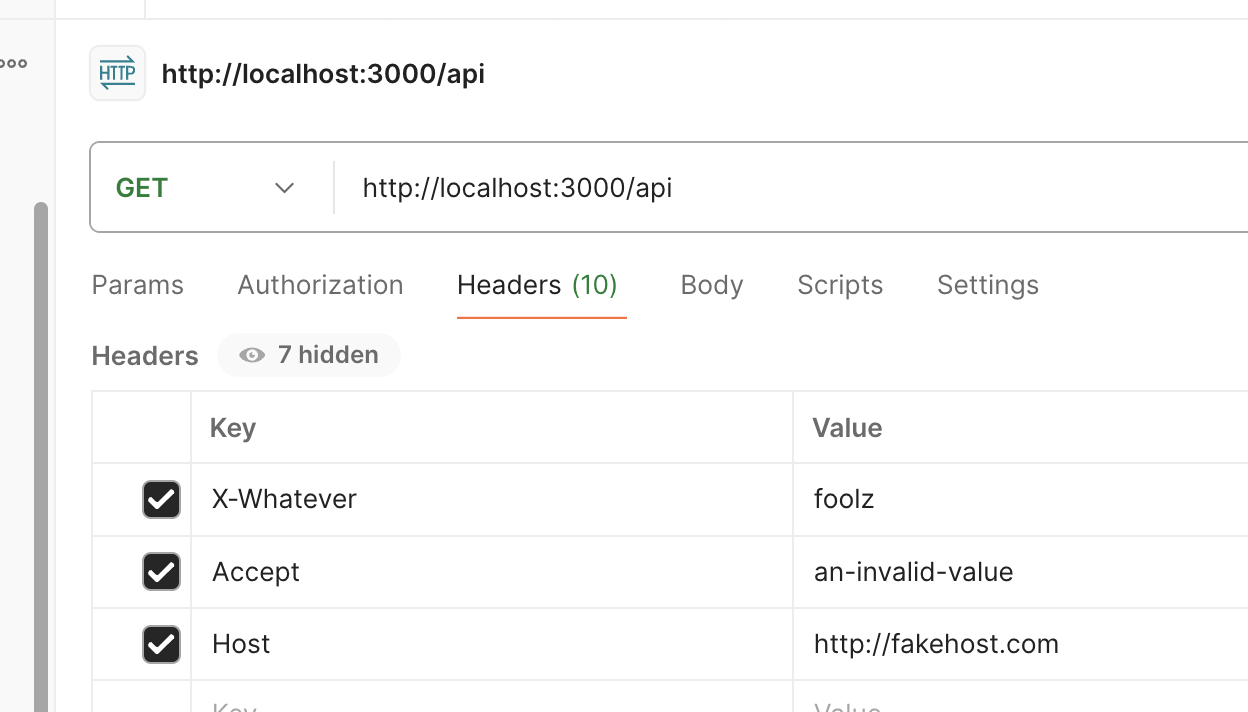
It works with curl too. In fact, executing a curl command in your code is one way to get around them in Node (Mehul Mohan's one of many who've likely done this):
const { spawn } = require("child_process");
spawn("curl", [
"-X",
"GET",
"http://localhost:3000/api",
"-H",
"Host: http://fakehost.com",
]);This is a good reminder that a specification's existence doesn't force a tool to respect it. Nothing on the internet can be completely, universally trusted.
Metadata Request Headers
Still, the laissez-faire, libertarian engineers out there might not like the fact that these "forbidden" headers exist. But I've come to appreciate them in certain cases. Consider the aforementioned content negotiation I was doing with PicPerf. I wanted real good confidence that a request was coming from a user navigating to my page in the browser. The Accept header would probably have been fine, but there's a set of forbidden request headers that are far more reliable: fetch metadata request headers.
These headers are intended to give a whole bunch of extra context about a request, which is often useful for a server to determine how to respond. And being "forbidden," you can have reasonably high confidence they weren't modified by anything other than the user agent.
To figure out if a request came from a user navigating to a page in the browser, these headers provide a number of options:
'sec-fetch-mode': 'navigate'
This value indicates the purpose of the request is to navigate between different HTML documents. It won't be set to this for any other request in the browser.
'sec-fetch-dest': 'document'
The request's destination is an HTML document, specifically triggered by top-level, user-initiated navigation. Even if a fetch() request were to try to ask for a document, by including text/html in the accept header, this sec- header would not be set to 'document'.
'sec-fetch-user': '?1',
This header will only exist if the request was triggered by direct user action (navigating between pages). It wouldn't even exist if the user clicked a button triggering a fetch() request. It's too far removed.
'sec-fetch-site': 'none',
The sec-fetch-site header is intended to give the server context about the origin of the requested resource (the same site, a different one, etc.). But it'll always be set to "none" if it's triggered by a user directly navigating to a page.
This makes it simple enough to determine whether any given request is from a user in the browser.
function isUserNavigation(headers) {
return (
headers["sec-fetch-dest"] === "document" &&
headers["sec-fetch-mode"] === "navigate" &&
headers["sec-fetch-site"] === "none" &&
headers["sec-fetch-user"] === "?1"
);
}Technically, any one of those checks would be sufficient. But I like to be thorough.
A Note About Edge Functions
In my tinkering, I came across something noteworthy regarding these sec-* headers and edge functions that may be modifying a request. Creating a new request context will prevent them from being passed down to origin.
Let's look back at that earlier Cloudflare function. This example creates an entirely new context, meaning all metadata request headers are not automatically included in the new request. Instead, you need to manually set them.
export default {
fetch(request) {
// Creating a *new* request...
const newRequest = new Request(
"https://some-new-url.com",
{
...request,
headers: {
...request.headers,
"sec-fetch-mode": request.headers["sec-fetch-mode"],
//... and so on
},
}
);
return fetch(newRequest);
},
};You're right to tilt your head at this. Apparently, in this particular runtime, those headers aren't as "forbidden" as they are elsewhere. Regardless, if you do want to include them automatically, see if you can get away with preserving the same request object.
export default {
fetch(request) {
return fetch("https://some-new-url.com", request);
},
};That'll make 'em stick. No manual setting required.
Browser Support is Good, Not Ubiquitous
The vast majority of users out there are on a browser that's supported these metadata request headers for some time now. But there may be a few stragglers out there. If that could affect you, it's fine to fall back to the accept header approach:
function isUserNavigation(headers) {
// Verify the header was passed...
if ("sec-fetch-mode" in headers) {
return (
headers["sec-fetch-dest"] === "document" &&
headers["sec-fetch-mode"] === "navigate" &&
headers["sec-fetch-site"] === "none" &&
headers["sec-fetch-user"] === "?1"
);
}
// If not...
return headers["accept"].includes("text/html")
&& !headers["accept"].includes("application/json");
}Of course, that'll depend on your minimum level of confidence. If it's very high, you might now fall back at all. Maybe you'd reject (or reroute) the request altogether. Up to you.
Don't Bet Your Life
It's worth saying again: the fact that a specification exists doesn't mean people and the tools they create will respect it. We've demonstrated that. Keep this in mind as you leverage sec-* and other forbidden headers. They provide some nice assurance as you size up an HTTP request, but you shouldn't bet your life on that assurance. That'd be stupid.
Get blog posts like this in your inbox.
May be irregular. Unsubscribe whenever.